![]()
Des chercheurs de l’université Stanford et de Google (Oriol Vinyals, Alexander Toshev, Samy Bengio et Dumitru Erhan) ont mis au point un modèle capable de détecter les différents éléments d’une photographie.
Jusqu’aujourd’hui, un ordinateur était capable d’identifier un élément d’une ressource graphique. On le voit par exemple sur les réseaux sociaux lorsque le système encadre les visages des personnes et demandent leur identification.
Ce mois-ci, un pas de plus a été franchi dans l’intelligence artificielle. Le modèle développé par les scientifiques de Google et de l’université de Stanford permet en effet :
- D’identifier automatiquement plusieurs éléments disponibles sur la même photographie.
- Générer une description de ces éléments avec des phrases complexes.
Cette reconnaissance visuelle fonctionne donc avec un système de transcription qui a été inspiré des progrès de la traduction automatique (traduction des éléments de l’image vers l’anglais)
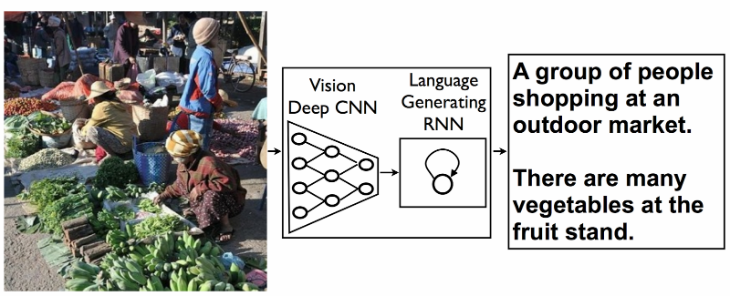
Ce système n’est pas encore totalement au point comme nous pouvons le voir sur la classification des ingénieurs Google : décrit sans erreurs, décrit avec des erreurs mineures, quelque chose en rapport avec l’image, pas de correspondance entre l’image et la description.

Les applications de ce modèle sont multiples, notamment dans le domaine du web. Les images que nous consultons chaque jour ont en effet des métadonnées mal renseignées (quand elles le sont !). La situation changera avec cet algorithme. Google images pourra en effet classer et archiver les images de façon plus fine. L’internaute pourra donc chercher l’intégralité des images contenant un objet donné par exemple.
Autre application : l’accessibilité. Actuellement, les lecteurs d’écran utilisés par les personnes malvoyantes lisent le contenu de la balise « alt » (texte alternatif). Ces balises sont remplies par les éditeurs de sites internet. Elles sont cependant souvent oubliées ou mal renseignées. Avec la reconnaissance logicielle du contenu des images, elles pourront avoir une description complète du contenu. Cela pourra également servir pour les connexions bas débits par exemple, en remplaçant les images trop lourdes par du vrai texte.
Il y a sans doute de nombreuses autres applications. N’hésitez-pas à enrichir cet article via les commentaires !
Bonne journée !
Sources : next inpact.
Pour plus d’informations : études des chercheurs de l’université de Stanford, et des chercheurs de Google