
Qu’est-ce que c’est ?
Lorsque vous souhaitez envoyer un formulaire de contact sur un site web, on vous demande de vérifier que vous n’êtes pas un robot mais bien une vraie personne qui souhaite réellement contacter l’entreprise derrière le formulaire.
Mais pourquoi cette démarche est-elle nécessaire et surtout est-ce réellement utile ?
L’entreprise propriétaire du site web souhaite s’assurer que vous n’êtes pas un robot, sous entendu un script ou un programme malveillant qui tenterait de compromettre la sécurité du site.

Exemples :
- Spam : Des spammeurs pourraient utiliser le formulaire de contact pour envoyer des messages en masse. Cela peut submerger la boîte de réception du destinataire, rendre le traitement des demandes légitimes plus difficile et nuire à l’expérience utilisateur.
- Attaques par force brute : Des pirates pourraient utiliser des attaques par force brute (tentatives successives et répétées) pour tenter de deviner les informations d’identification d’un utilisateur ou les adresses e-mail en essayant différentes combinaisons. Cela peut aboutir à des comptes compromis et à des violations de sécurité.
CAPTCHA = Completely Automated Public Turing test to tell Computers and Humans Apart
Littéralement, un CAPTCHA est un procédé de test inversé du test de Turing.
Le test de Turing (décrit par M. Turing himself dans les années 50) consiste à confronter un être humain face à une machine d’une part et un humain d’autre part. L’objectif est de tenter de différencier l’humain de la machine, si cela n’est pas possible alors cela veut dire que la machine est capable de penser.

Le concept du CAPTCHA repose sur la distinction entre les machines et les êtres humains, en se basant sur des aptitudes propres à l’humain que les machines ne pourraient théoriquement jamais acquérir.
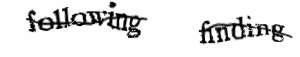
Dans l’exemple ci-dessus, ce test confronte la machine à quelque chose qu’elle ne connaît pas : la logique de la sémantique, à savoir à quel moment un mot s’arrête et un autre commence.
Dans la théorie, tout cela fonctionne, ou en tous cas, cela fonctionnait.
Les contournements de CAPTCHA
Utilisation de techniques de Deep Learning
Ces CAPTCHA qui fonctionnaient bien jusque dans les années 2010 sont obsolètes aujourd’hui. Pour les contourner, il est possible de créer un script qui permet de réaliser un “denoising” sur l’image, puis de séparer les caractères les uns des autres, et le tour est joué.
Avec les techniques de deep learning, ces scripts ont même fini par obtenir des meilleurs scores de résolution de CAPTCHA que les être humains.
(avouez que vous aussi vous avez parfois demandé un refresh du CAPTCHA parce que vous ne parveniez par à le lire ?)
Les questions en toutes lettres > ask ChatGPT
Les CAPTCHA simples qui consistaient en une question écrite en toutes lettres, typiquement “Combien font deux plus deux” étaient jusqu’à il y a peu, très utilisés pour sécuriser des forums. Ils étaient simples à mettre en place et efficaces : les robots peuvent résoudre des problèmes de maths, mais seulement avec des chiffres.
Mais c’était sans compter sur un certain Chatgpt…
Chatgpt étant programmé pour répondre à des questions, rien de plus simple !
Une main d’œuvre gratuite pour Google ?
Google profite de l’utilisation de ses CAPTCHA par un grand nombre de personnes pour entraîner son intelligence artificielle et aussi pour numériser des documents.
En 2006, au lancement du programme de numérisation on estimait que 200 millions de CAPTCHA étaient déchiffrés chaque jour, de quoi réaliser rapidement de simples opérations, comme des séparations de mots, typiquement le genre de problèmes posés lorsqu’un algorithme ne peut pas déchiffrer automatiquement un mot.
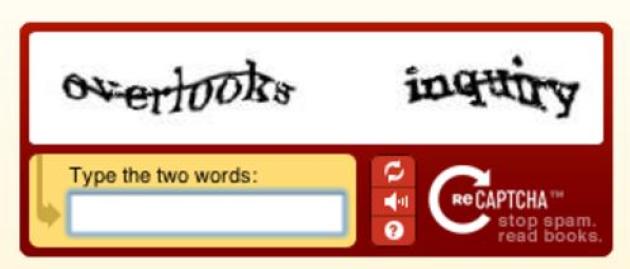
Les CAPTCHA à textes ont ainsi permis d’aider à numériser les archives du New York Times, ainsi que la bibliothèque Google Books.
Dans l’exemple ci-dessous, le second mot est tiré d’un ouvrage à numériser. Les algorithmes de reconnaissance de caractères ayant leurs limites, certains termes n’ont pas pu être déchiffrés automatiquement, c’est là que l’intervention humaine est nécessaire.
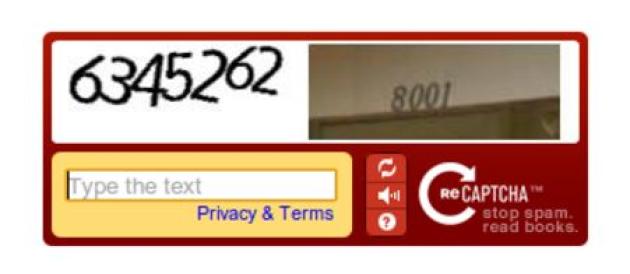
Les CAPTCHA présentant des chiffres ont eux permis d’améliorer Google Street View, en déterminant les numéros de maisons ou des panneaux routiers.
Aujourd’hui, les CAPTCHA Google servent à améliorer les programmes de reconnaissance d’images, notamment en vue d’entraîner les IA de véhicules autonomes. C’est pourquoi on vous demande parfois de cliquer sur des images de feux rouges, vélos, etc.
Les CAPTCHA sont-ils vraiment inutiles ?
D’après ce que nous avons vu jusqu’ici, les CAPTCHA sont loin d’être infaillibles… et ont surtout servi à d’autres activités, comme l’amélioration des outils Google.
Cependant, depuis les premières versions, ces tests ont bien évolué et ont permis de faire de grandes avancées.
Et c’est justement ça l’objectif : le propre d’un test de sécurité est d’être contourné, et c’est l’objectif derrière les CAPTCHA, selon les chercheurs d’IBM qui travaillent sur le sujet.
Plus une sécurité va être contournée, plus celle-ci devra être améliorée et plus elle va amener à des découvertes intéressantes.
Existe-t-il d’autres techniques de sécurité ?
Le CAPTCHA nouvelle génération chez Google
La dernière version du reCAPTCHA de Google est désormais invisible, elle analyse le comportement de l’utilisateur pendant sa navigation. C’est une combinaison de machine learning qui permet une analyse de risque avancée.
Cette version n’est pas appréciée en matière de protection des données puisqu’on ne sais pas réellement dans quelle mesure elle analyse le comportement des utilisateurs : on sait que les cookies sont utilisés, les mouvements de la souris ainsi que d’autres éléments potentiellement (il faut accepter les même conditions générales d’utilisation que pour les autres services Google pour installer ce reCAPTCHA).
Le honeypot
Vous avez bien lu, c’est la technique du pot de miel, comme pour attraper les insectes.

Concrètement, dans le cadre d’un formulaire de contact, cette technique protège de la soumission de spams automatisés ou de robots malveillants. Cette méthode exploite le fait que les bots ne peuvent pas faire la distinction entre des champs de formulaire visibles et invisibles pour les utilisateurs humains.
Concrètement, voici le fonctionnement du pot de miel :
1 > On ajoute un champ caché dans le formulaire
2 > Il est nommé d’une façon à être considéré comme vrai pour les robots
3 > On applique une règle côté serveur qui vérifie si ce champ est rempli ou non
4 > On applique le bon traitement si le champ est rempli : le formulaire est rejeté ; si le champ n’est pas rempli, on peut considérer que le formulaire est bien légitime.
L’avantage de l’utilisation d’un honeypot est qu’il n’exige pas d’action de la part du visiteur, ce qui est intéressant d’un point de vue expérience utilisateur. Les utilisateurs humains ne voient pas le champ caché et n’ont pas besoin d’effectuer d’actions supplémentaires, pendant que les robots malveillants seront rapidement identifiés et bloqués.
D’une manière générale, même si le risque zéro n’existe pas, il est préférable de sécuriser un formulaire sur un site web, que ce soit avec un CAPTCHA, un honeypot, ou tout autre technique qui ne pourrait pas être détournée par un robot.
Et pour ne rien louper de nos actualités,
suivez-nous sur les réseaux
Retrouvez aussi :

L’accessibilité numérique, qu’est-ce que c’est ?
L’accessibilité numérique consiste à rendre possible l’accès à l’information et aux fonctionnalités numériques aux personnes en situation de handicap.

Le web écologique : les bonnes pratiques
Le site web durable est à l’air du temps. Au cours des dernières années, ce sujet fait de plus en plus de bruit. Les divers métiers du design tendent vers une approche plus durable.